Cercetările desfășurate vizează crearea unui cadru unitar pentru interpretarea datelor vizuale captate de platforme aeriene (UAV), trecând de la procesarea pixelilor la reprezentări semantice și structurale complexe.
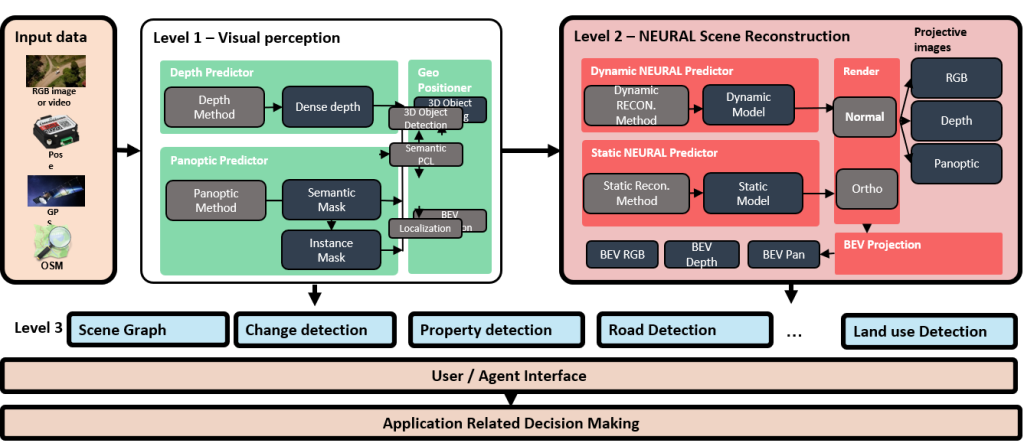
Arhitectura de percepție pe trei niveluri
Sistemul este organizat ierarhic pentru a transforma datele brute în decizii fundamentate:
- Nivelul 1 – Percepția Vizuală (Visual Perception): Se concentrează pe extragerea trăsăturilor fundamentale din imagini RGB sau fluxuri video. Include predictori pentru adâncime densă (Dense Depth), metode de segmentare panoptică (generarea măștilor semantice și de instanță) și algoritmi de detecție a obiectelor în spațiul 3D.
- Nivelul 2 – Reconstrucția Neurală a Scenei (Neural Scene Reconstruction): Utilizează predictori neurali statici și dinamici pentru a genera modele 3D. Această etapă permite randarea de imagini proiective, hărți de adâncime, vederi ortografice (Ortho) și proiecții de tip Bird’s Eye View (BEV). De asemenea, se realizează localizarea pe hărți de tip Open Street Map (OSM).
- Nivelul 3 – Graful de Scene (Scene Graph): Reprezintă nivelul superior de abstractizare unde se realizează detecția schimbărilor, analiza proprietăților drumurilor și detectarea modului de utilizare a terenului (Land use Detection). Acesta servește drept interfață pentru agentul de luare a deciziilor.
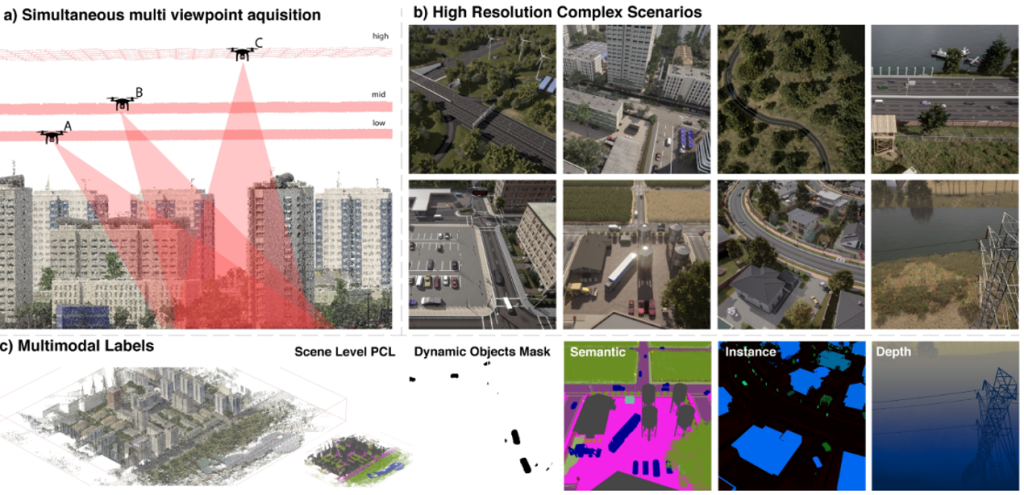
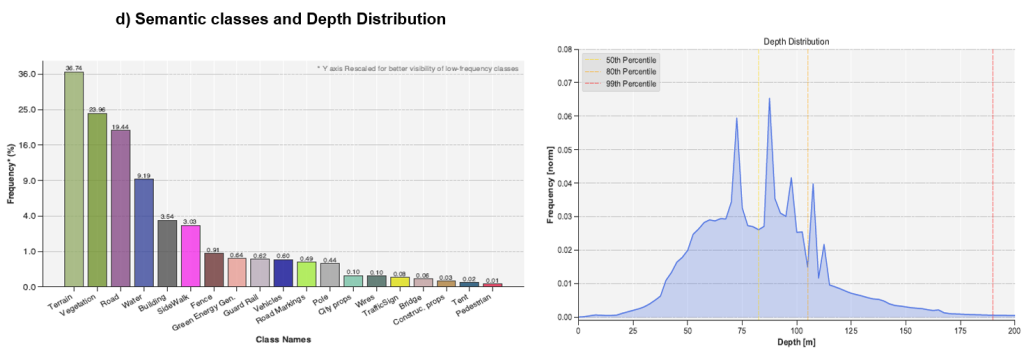
Dataset-ul sintetic ClaraVid
Pentru a antrena modele capabile să gestioneze scenarii complexe, a fost dezvoltat setul de date ClaraVid, care oferă avantaje majore față de seturile tradiționale:
- Achiziție Multi-View: Permite captarea simultană din multiple puncte de vedere (High, Mid, Low angle) pentru scenarii de înaltă rezoluție.
- Etichetare Multimodală Completă: Include nori de puncte (PCL) la nivel de scenă, măști pentru obiecte dinamice, segmente panoptice (semantice și de instanță) și hărți de adâncime precise.
- Accesibilitate: Datele sunt disponibile public pe platforma Hugging Face: huggingface.co/datasets/radubeche/claravid.
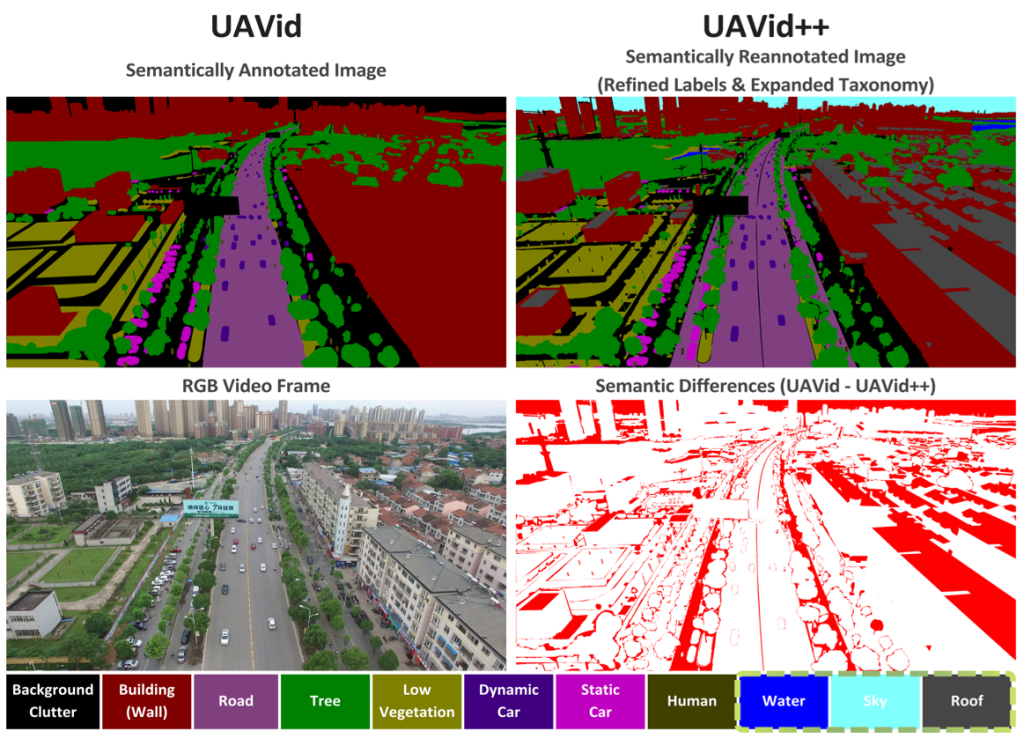
UAVid++ – Segmentare semantică avansată pentru imagini UAV
Percepția vizuală în scenarii aeriene (UAV) ridică provocări semnificative comparativ cu imaginile la nivelul solului. Printre principalele dificultăți se numără:
- variații extreme de scară (de la clădiri mari la obiecte foarte mici precum pietoni sau vehicule îndepărtate)
- densitate ridicată în zone urbane
- ambiguități vizuale cauzate de unghiuri de observație și altitudine
Dataset-urile existente, inclusiv UAVid, prezintă limitări importante:
- adnotări coarse (aproximative)
- inconsistențe semantice între clase
- lipsa detaliilor fine la nivel de contur
Aceste limitări afectează direct performanța modelelor de segmentare, în special în ceea ce privește obiectele mici și generalizarea în scenarii noi.
Pentru a depăși aceste limitări, am dezvoltat UAVid++, o versiune îmbunătățită semnificativ a dataset-ului UAVid, care introduce:
Adnotări de înaltă fidelitate
- corectarea manuală și automată a etichetelor existente
- aliniere semantică riguroasă între cadre
- contururi mult mai precise la nivel de pixel
Taxonomie semantică extinsă
- introducerea de clase suplimentare relevante pentru scenarii aeriene (ex: apă, cer, acoperișuri)
- structură mai coerentă și compatibilă cu alte dataset-uri UAV
- suport pentru evaluări out-of-distribution
Segmentare fină în scenarii complexe
- îmbunătățirea reprezentării obiectelor mici și aglomerate
- separare mai clară între instanțe apropiate
- reducerea ambiguităților în zone urbane dense
Integrarea modelelor de tip Large Vision Models (LVM)
Pentru a valorifica pe deplin noul dataset, s-a propus o arhitectură hibridă care combină:
- backbone DINO (self-supervised Vision Transformer)
→ oferă reprezentări semantice robuste și capacitate excelentă de generalizare - head inspirat din U-Net
→ recuperează detalii spațiale fine și îmbunătățește precizia contururilor
Această combinație abordează un compromis esențial în percepția vizuală:
- modelele mari (LVM) → înțeleg bine contextul global, dar pierd detalii fine
- modelele specializate → oferă precizie locală, dar generalizează mai slab
Prin integrarea lor, obținem un model capabil să gestioneze simultan contextul global și detaliul local.
Experimentele realizate demonstrează îmbunătățiri consistente:
- Generalizare superioară
Modelele antrenate pe UAVid++ performează robust pe scene, altitudini și orientări diferite ale camerei. - Segmentare îmbunătățită a obiectelor mici
Detectarea și delimitarea obiectelor de dimensiuni reduse este semnificativ mai precisă. - Contururi mai clare și mai stabile
Marginile obiectelor sunt mai bine definite, reducând erorile de clasificare la granițe. - Calitate apropiată de ground truth
Nivelul ridicat al adnotărilor permite utilizarea dataset-ului pentru:- knowledge distillation
- evaluări riguroase ale modelelor
- benchmark-uri realiste
Estimarea adâncimii monoculare și scalarea geo-informată
O provocare majoră în percepția aeriană este obținerea unei adâncimi metrice corecte din imagini monoculare. Soluția propusă include:
- UAVid-3D-Scenes: O extensie a setului semantic UAVid, axată pe adâncime, care permite cercetarea comună a sarcinilor semantice și 3D.
- Integrarea TanDEM-X GDEM: Se utilizează date globale de elevație (Digital Elevation Model) pentru a asigura o scalare metrică corectă a modelelor de adâncime relativă.
- Fluxul de Procesare a Datelor Real-World:
- Alinierea coordonatelor GPS cu imagini satelitare pentru setul UAVid.
- Utilizarea algoritmului Cloth Simulation Filter (CSF) pentru segmentarea eficientă a solului.
- Proiecția și mascarea datelor pentru corelarea precisă între cadrele camerei și modelul digital de teren.
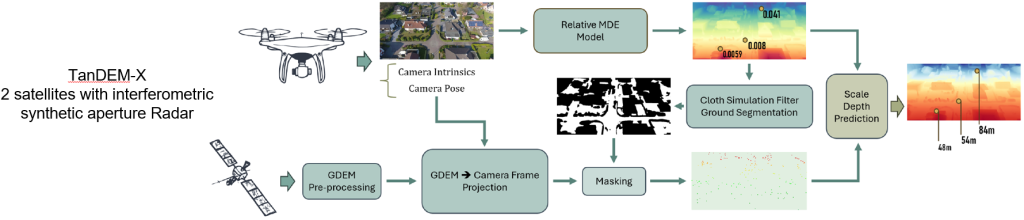
UAVid-3D-Scenes – Extensie orientată pe adâncime
UAVid-3D-Scenes reprezintă o extensie a dataset-ului UAVid, orientată către integrarea informației de adâncime, pentru a permite aplicații care combină date semantice și 3D. Dataset-ul este disponibil public pe HuggingFace: huggingface.co/datasets/hrflr/uavid-3d-scenes
Dataset-ul include:
- adâncime densă și rară
- alinierea cadrelor UAVid la coordonate globale (folosind GPS și imagini satelitare)
Pentru fiecare cadru, sunt integrate date din modelul de elevație TanDEM-X (GDEM), utilizate pentru proiecția informației de teren.
De asemenea, sunt utilizate reconstrucții 3D din UFO Depth dataset pentru evaluări out-of-distribution.
Scopul este îmbunătățirea scalării metrice a estimărilor de adâncime, prin combinarea informațiilor de poziție, altitudine și modele digitale de teren.

